Optimizing Your 2016 March Madness Bracket
In the days leading up to the NCAA tournament, the internet is hit with a slew of articles promising a definitive ‘tips and tricks’ guide to winning your March Madness pool. These articles always preach a derivative of one of the following strategies:
- Pick these teams that have the best chance of winning
- Pick these teams that no one else is taking
Strategy 1 is designed to maximize your bracket’s average performance on an absolute basis, and Strategy 2 is designed to maximize your bracket’s best performance relative to the rest of the pool. Of course, neither strategy maximizes what you actually care about — your chance of winning the pool. Correct picks don’t matter if everyone makes the same pick, and contrarian picks don’t matter if they are never right. The strategy that optimizes your chance of winning is somewhere in the middle:
For any given game in the tournament, the contribution of a pick towards your chance of winning is a function of the odds that pick is correct and the odds that the rest of the pool isn’t making the same pick:
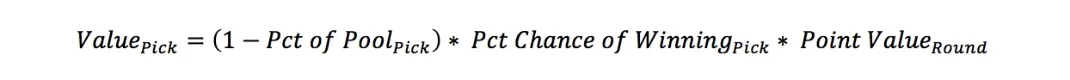
The value of a bracket is the sum of the values of all its picks, and the bracket that maximizes your chance of winning is the one with the highest value. Luckily, all the variables in this optimization problem are (somewhat) readily available.
The chance that a team will make it to a specific round is provided as a .CSV by fivethirtyeight.com here. The percentage of users picking a team in a specific round (e.g. the percentage of your pool picking that team) can be compiled through the CBS sports API with this python script.
With this data, I created a model for optimizing a bracket, which is located here. Though optimization software can make things faster, you can optimize a bracket manually through backwards selection on the second tab (start with winner of the championship game and move backwards by picking the teams with the highest pick value in a given round). With backwards selection you can also subjectively select a Final Four and then optimize the first four rounds around those four picks. The following bracket optimizes for all rounds based on point values of 1, 2, 4, 8, 16, and 32 for the 1st, 2nd, Sweet Sixteen, Elite Eight, Final Four, and Championship rounds respectively:

The most interesting take-away from this bracket is the prevalence of top seeds in the Final Four (three 1 seeds and one 2 seed). Despite being popular picks, these teams have significantly higher chances of reaching the Final Four than the rest of the field. Also interesting is the number of upsets in the first round. Round one favorites that are not optimal picks in the second round are easy targets for upsets in the first round, even if they are unlikely to actually lose.
The key to understanding this model is knowing that it does not predict the most likely winners, but rather, the most valuable winners. For instance, Michigan State has a much higher chance of moving to the Elite Eight than Utah, but picking Utah is expected to contribute more value to a bracket in the average pool because Michigan State is such a commonly picked team.
NCAA pool strategy is an interesting mix of probability and game theory concepts. It's easy to optimize for one or the other, but difficult to mesh them together. This model isn't perfect, and probably underestimates the optionality of extremely contrarian picks, but I'd like to believe it's a bit better than what's offered by the 'Win Your Bracket with These 5 Easy Tricks' types of headlines. Good luck and have fun!